
Last Updated: July 15, 2022
Part 7: Add Doublet Detection
Doublets are cells that appear to be, but are not, real cells. There are two major types of doublets: heterotypic and homotypic. Heterotypic doublets are formed by cells with distinct transcriptional profiles. Homotypic doublets are formed by cells with similar transcriptional profiles. Heterotypic doublets are relatively easier to detect compared with homotypic doublets. Depending on the protocols used to barcode single cells/nuclei, doublet rates vary significantly and it can reach as high as 40%.
Experimental strategies have been developed to reduce the doublet rate, such as cell hashing, demuxlet, and MULTI-Seq. However, these techniques require extra steps in sample preparation which leads to extra costs, time and they do not guarantee to remove all doublets.
Naturally, removing doublets in silico is very appealing and there have been many tools/methods developed to achieve this: DoubletFinder, DoubletDetection(https://github.com/JonathanShor/DoubletDetection), DoubletDecon, among others.
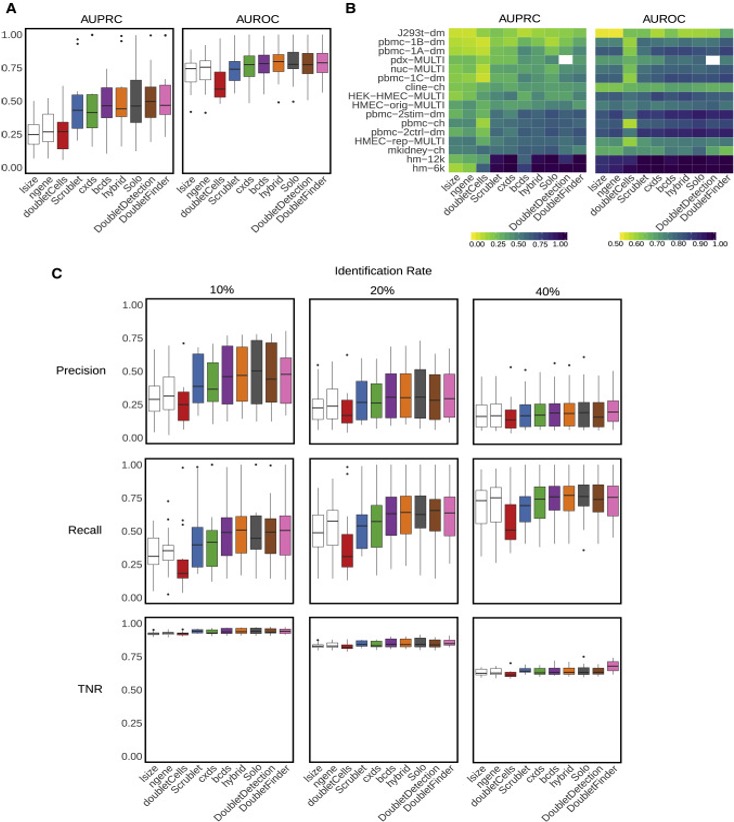
Xi, etc., Cell Systems, 2021, https://www.sciencedirect.com/science/article/pii/S2405471220304592
Doublet detection with DoubletFinder
DoubletFinder takes fully pre-processed data from Seurat (NormalizeData, FindVariableGenes, ScaleData, RunPCA and RunTSNE) as input and the process should be done for each sample individually. The input data should be processed to remove low-quality cell clusters first.
We are going to run DoubletFinder on sample A001-C-007.
We start each markdown document with installing/loading needed libraries for R:
# must install DoubletFinder
if (!any(rownames(installed.packages()) == "DoubletFinder")){
remotes::install_github('chris-mcginnis-ucsf/DoubletFinder')
}
library(DoubletFinder)
# must have Seurat
library(Seurat)
library(kableExtra)
library(ggplot2)
Setup the experiment folder and data info
experiment_name = "Colon Cancer"
dataset_loc <- "./expression_data_cellranger"
ids <- c("A001-C-007", "A001-C-104", "B001-A-301")
Load the Cell Ranger Matrix Data and create the base Seurat object.
This section is done the same way as in scRNA_Workshop-PART1.Rmd
Seurat provides a function Read10X and Read10X_h5 to read in 10X data folder. First we read in data from each individual sample folder.
Later, we initialize the Seurat object (CreateSeuratObject) with the raw (non-normalized data). Keep all cells with at least 200 detected genes. Also extracting sample names, calculating and adding in the metadata mitochondrial percentage of each cell. Adding in the metadata batchid and cell cycle. Finally, saving the raw Seurat object.
Load the Cell Ranger Matrix Data (hdf5 file) and create the base Seurat object.
d10x.data <- lapply(ids[1], function(i){
d10x <- Read10X_h5(file.path(dataset_loc, i, "outs","raw_feature_bc_matrix.h5"))
colnames(d10x) <- paste(sapply(strsplit(colnames(d10x),split="-"),'[[',1L),i,sep="-")
d10x
})
names(d10x.data) <- ids[1]
str(d10x.data)
## List of 1
## $ A001-C-007:Formal class 'dgCMatrix' [package "Matrix"] with 6 slots
## .. ..@ i : int [1:16845098] 13849 300 539 916 2153 2320 3196 4057 4317 4786 ...
## .. ..@ p : int [1:1189230] 0 1 1 100 101 102 103 240 241 241 ...
## .. ..@ Dim : int [1:2] 36601 1189229
## .. ..@ Dimnames:List of 2
## .. .. ..$ : chr [1:36601] "MIR1302-2HG" "FAM138A" "OR4F5" "AL627309.1" ...
## .. .. ..$ : chr [1:1189229] "AAACCCAAGAAACCCA-A001-C-007" "AAACCCAAGAAACCCG-A001-C-007" "AAACCCAAGAAACTGT-A001-C-007" "AAACCCAAGAAAGCGA-A001-C-007" ...
## .. ..@ x : num [1:16845098] 1 1 1 1 1 1 1 1 1 1 ...
## .. ..@ factors : list()
If you don’t have the needed hdf5 libraries you can read in the matrix files like such
d10x.data <- sapply(ids[1], function(i){
d10x <- Read10X(file.path(dataset_loc, i, "/outs","raw_feature_bc_matrix"))
colnames(d10x) <- paste(sapply(strsplit(colnames(d10x), split="-"), '[[', 1L), i, sep="-")
d10x
})
names(d10x.data) <- ids[1]
Create the Seurat object
Filter criteria: remove genes that do not occur in a minimum of 0 cells and remove cells that don’t have a minimum of 200 features/genes
experiment.data <- CreateSeuratObject(
d10x.data[[1]],
project = "A001-C-007",
min.cells = 0,
min.features = 200,
names.field = 2,
names.delim = "\\-")
The percentage of reads that map to the mitochondrial genome
- Low-quality / dying cells often exhibit extensive mitochondrial contamination.
- We calculate mitochondrial QC metrics with the PercentageFeatureSet function, which calculates the percentage of counts originating from a set of features.
- We use the set of all genes, in mouse these genes can be identified as those that begin with ‘mt’, in human data they begin with MT.
experiment.data$percent.mito <- PercentageFeatureSet(experiment.data, pattern = "^MT-")
summary(experiment.data$percent.mito)
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.000 2.283 3.285 3.324 4.255 46.647
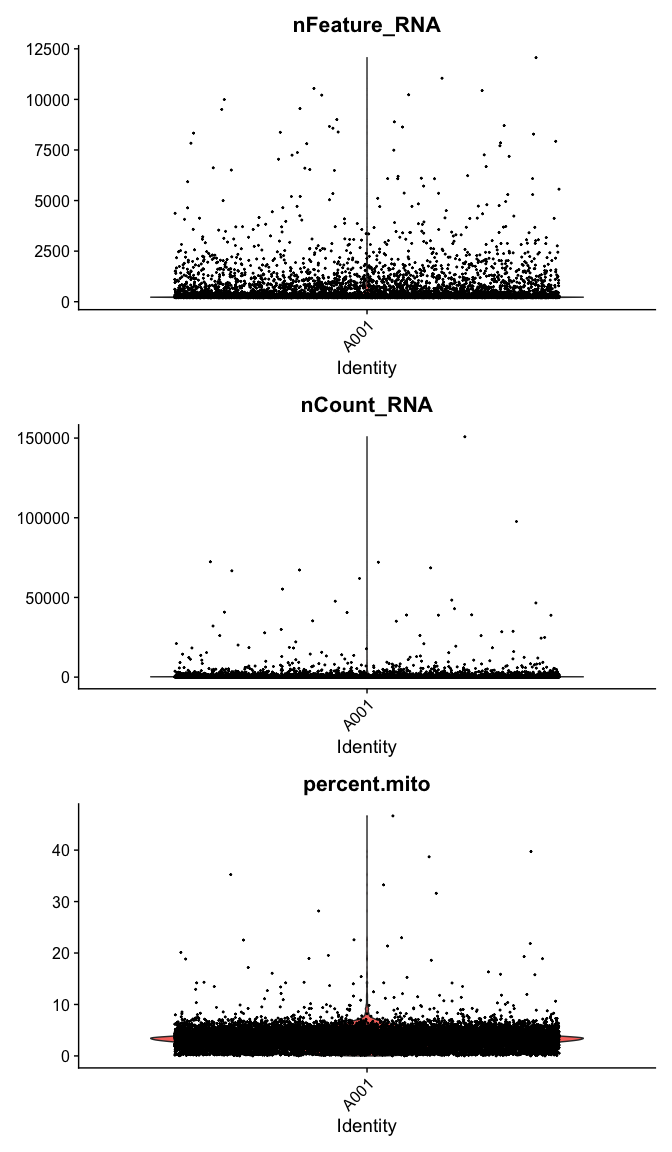
Violin plot of 1) number of genes, 2) number of UMI and 3) percent mitochondrial genes
VlnPlot(
experiment.data,
features = c("nFeature_RNA", "nCount_RNA","percent.mito"),
ncol = 1, pt.size = 0.3)
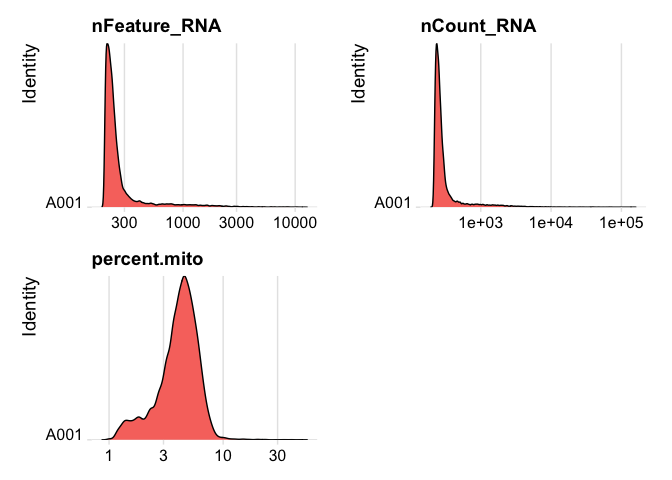
plot ridge plots of the same data
RidgePlot(experiment.data, features=c("nFeature_RNA","nCount_RNA", "percent.mito"), log=T, ncol = 2)
Cell filtering
We use the information above to filter out cells. Here we choose those that have percent mitochondrial genes max of 8%, unique UMI counts under 1,000 or greater than 12,000 and contain at least 400 features within them.
table(experiment.data$orig.ident)
##
## A001
## 17908
experiment.data <- subset(experiment.data, percent.mito <= 8)
experiment.data <- subset(experiment.data, nFeature_RNA >= 400 & nFeature_RNA <= 4000)
experiment.data <- subset(experiment.data, nCount_RNA >= 500 & nCount_RNA <= 12000)
experiment.data
## An object of class Seurat
## 36601 features across 1777 samples within 1 assay
## Active assay: RNA (36601 features, 0 variable features)
table(experiment.data$orig.ident)
##
## A001
## 1777
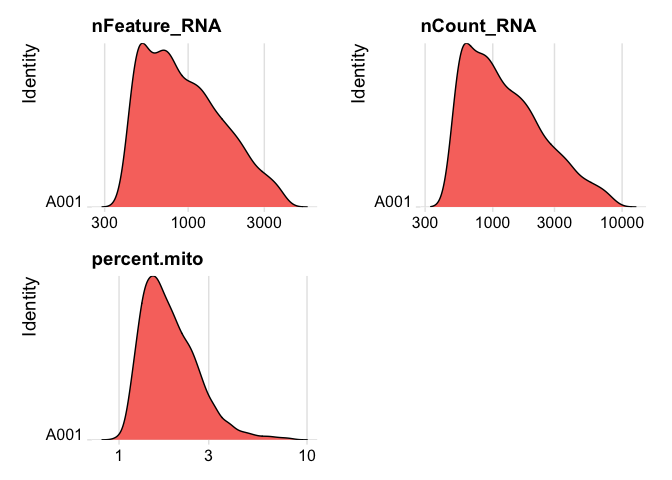
Lets se the ridge plots now after filtering
RidgePlot(experiment.data, features=c("nFeature_RNA","nCount_RNA", "percent.mito"), log=T, ncol = 2)
experiment.data <- NormalizeData(experiment.data)
experiment.data <- FindVariableFeatures(experiment.data, selection.method = "vst", nfeatures = 2000)
experiment.data <- ScaleData(experiment.data)
experiment.data <- RunPCA(experiment.data)
experiment.data <- FindNeighbors(experiment.data, reduction="pca", dims = 1:20)
experiment.data <- FindClusters(
object = experiment.data,
resolution = seq(0.25,4,0.5),
verbose = FALSE
)
experiment.data <- RunUMAP(experiment.data, dims=1:20)
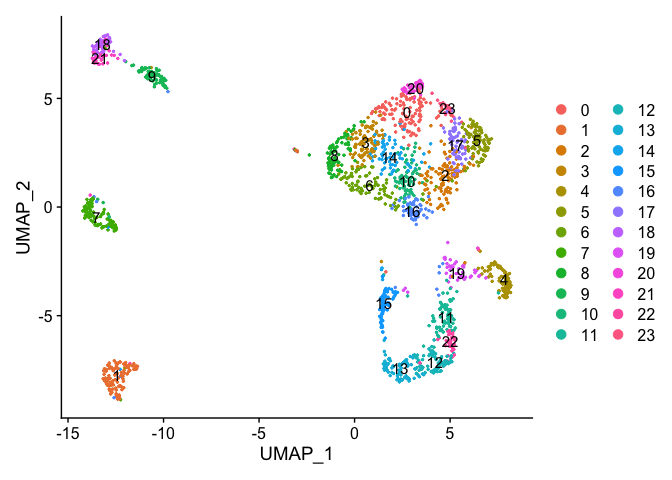
DimPlot(object = experiment.data, pt.size=0.5, reduction = "umap", label = T)
sweep.res <- paramSweep_v3(experiment.data, PCs = 1:20, sct = FALSE)
## [1] "Creating artificial doublets for pN = 5%"
## [1] "Creating Seurat object..."
## [1] "Normalizing Seurat object..."
## [1] "Finding variable genes..."
## [1] "Scaling data..."
## [1] "Running PCA..."
## [1] "Calculating PC distance matrix..."
## [1] "Defining neighborhoods..."
## [1] "Computing pANN across all pK..."
## [1] "pK = 0.01..."
## [1] "pK = 0.02..."
## [1] "pK = 0.03..."
## [1] "pK = 0.04..."
## [1] "pK = 0.05..."
## [1] "pK = 0.06..."
## [1] "pK = 0.07..."
## [1] "pK = 0.08..."
## [1] "pK = 0.09..."
## [1] "pK = 0.1..."
## [1] "pK = 0.11..."
## [1] "pK = 0.12..."
## [1] "pK = 0.13..."
## [1] "pK = 0.14..."
## [1] "pK = 0.15..."
## [1] "pK = 0.16..."
## [1] "pK = 0.17..."
## [1] "pK = 0.18..."
## [1] "pK = 0.19..."
## [1] "pK = 0.2..."
## [1] "pK = 0.21..."
## [1] "pK = 0.22..."
## [1] "pK = 0.23..."
## [1] "pK = 0.24..."
## [1] "pK = 0.25..."
## [1] "pK = 0.26..."
## [1] "pK = 0.27..."
## [1] "pK = 0.28..."
## [1] "pK = 0.29..."
## [1] "pK = 0.3..."
## [1] "Creating artificial doublets for pN = 10%"
## [1] "Creating Seurat object..."
## [1] "Normalizing Seurat object..."
## [1] "Finding variable genes..."
## [1] "Scaling data..."
## [1] "Running PCA..."
## [1] "Calculating PC distance matrix..."
## [1] "Defining neighborhoods..."
## [1] "Computing pANN across all pK..."
## [1] "pK = 0.01..."
## [1] "pK = 0.02..."
## [1] "pK = 0.03..."
## [1] "pK = 0.04..."
## [1] "pK = 0.05..."
## [1] "pK = 0.06..."
## [1] "pK = 0.07..."
## [1] "pK = 0.08..."
## [1] "pK = 0.09..."
## [1] "pK = 0.1..."
## [1] "pK = 0.11..."
## [1] "pK = 0.12..."
## [1] "pK = 0.13..."
## [1] "pK = 0.14..."
## [1] "pK = 0.15..."
## [1] "pK = 0.16..."
## [1] "pK = 0.17..."
## [1] "pK = 0.18..."
## [1] "pK = 0.19..."
## [1] "pK = 0.2..."
## [1] "pK = 0.21..."
## [1] "pK = 0.22..."
## [1] "pK = 0.23..."
## [1] "pK = 0.24..."
## [1] "pK = 0.25..."
## [1] "pK = 0.26..."
## [1] "pK = 0.27..."
## [1] "pK = 0.28..."
## [1] "pK = 0.29..."
## [1] "pK = 0.3..."
## [1] "Creating artificial doublets for pN = 15%"
## [1] "Creating Seurat object..."
## [1] "Normalizing Seurat object..."
## [1] "Finding variable genes..."
## [1] "Scaling data..."
## [1] "Running PCA..."
## [1] "Calculating PC distance matrix..."
## [1] "Defining neighborhoods..."
## [1] "Computing pANN across all pK..."
## [1] "pK = 0.01..."
## [1] "pK = 0.02..."
## [1] "pK = 0.03..."
## [1] "pK = 0.04..."
## [1] "pK = 0.05..."
## [1] "pK = 0.06..."
## [1] "pK = 0.07..."
## [1] "pK = 0.08..."
## [1] "pK = 0.09..."
## [1] "pK = 0.1..."
## [1] "pK = 0.11..."
## [1] "pK = 0.12..."
## [1] "pK = 0.13..."
## [1] "pK = 0.14..."
## [1] "pK = 0.15..."
## [1] "pK = 0.16..."
## [1] "pK = 0.17..."
## [1] "pK = 0.18..."
## [1] "pK = 0.19..."
## [1] "pK = 0.2..."
## [1] "pK = 0.21..."
## [1] "pK = 0.22..."
## [1] "pK = 0.23..."
## [1] "pK = 0.24..."
## [1] "pK = 0.25..."
## [1] "pK = 0.26..."
## [1] "pK = 0.27..."
## [1] "pK = 0.28..."
## [1] "pK = 0.29..."
## [1] "pK = 0.3..."
## [1] "Creating artificial doublets for pN = 20%"
## [1] "Creating Seurat object..."
## [1] "Normalizing Seurat object..."
## [1] "Finding variable genes..."
## [1] "Scaling data..."
## [1] "Running PCA..."
## [1] "Calculating PC distance matrix..."
## [1] "Defining neighborhoods..."
## [1] "Computing pANN across all pK..."
## [1] "pK = 0.01..."
## [1] "pK = 0.02..."
## [1] "pK = 0.03..."
## [1] "pK = 0.04..."
## [1] "pK = 0.05..."
## [1] "pK = 0.06..."
## [1] "pK = 0.07..."
## [1] "pK = 0.08..."
## [1] "pK = 0.09..."
## [1] "pK = 0.1..."
## [1] "pK = 0.11..."
## [1] "pK = 0.12..."
## [1] "pK = 0.13..."
## [1] "pK = 0.14..."
## [1] "pK = 0.15..."
## [1] "pK = 0.16..."
## [1] "pK = 0.17..."
## [1] "pK = 0.18..."
## [1] "pK = 0.19..."
## [1] "pK = 0.2..."
## [1] "pK = 0.21..."
## [1] "pK = 0.22..."
## [1] "pK = 0.23..."
## [1] "pK = 0.24..."
## [1] "pK = 0.25..."
## [1] "pK = 0.26..."
## [1] "pK = 0.27..."
## [1] "pK = 0.28..."
## [1] "pK = 0.29..."
## [1] "pK = 0.3..."
## [1] "Creating artificial doublets for pN = 25%"
## [1] "Creating Seurat object..."
## [1] "Normalizing Seurat object..."
## [1] "Finding variable genes..."
## [1] "Scaling data..."
## [1] "Running PCA..."
## [1] "Calculating PC distance matrix..."
## [1] "Defining neighborhoods..."
## [1] "Computing pANN across all pK..."
## [1] "pK = 0.01..."
## [1] "pK = 0.02..."
## [1] "pK = 0.03..."
## [1] "pK = 0.04..."
## [1] "pK = 0.05..."
## [1] "pK = 0.06..."
## [1] "pK = 0.07..."
## [1] "pK = 0.08..."
## [1] "pK = 0.09..."
## [1] "pK = 0.1..."
## [1] "pK = 0.11..."
## [1] "pK = 0.12..."
## [1] "pK = 0.13..."
## [1] "pK = 0.14..."
## [1] "pK = 0.15..."
## [1] "pK = 0.16..."
## [1] "pK = 0.17..."
## [1] "pK = 0.18..."
## [1] "pK = 0.19..."
## [1] "pK = 0.2..."
## [1] "pK = 0.21..."
## [1] "pK = 0.22..."
## [1] "pK = 0.23..."
## [1] "pK = 0.24..."
## [1] "pK = 0.25..."
## [1] "pK = 0.26..."
## [1] "pK = 0.27..."
## [1] "pK = 0.28..."
## [1] "pK = 0.29..."
## [1] "pK = 0.3..."
## [1] "Creating artificial doublets for pN = 30%"
## [1] "Creating Seurat object..."
## [1] "Normalizing Seurat object..."
## [1] "Finding variable genes..."
## [1] "Scaling data..."
## [1] "Running PCA..."
## [1] "Calculating PC distance matrix..."
## [1] "Defining neighborhoods..."
## [1] "Computing pANN across all pK..."
## [1] "pK = 0.01..."
## [1] "pK = 0.02..."
## [1] "pK = 0.03..."
## [1] "pK = 0.04..."
## [1] "pK = 0.05..."
## [1] "pK = 0.06..."
## [1] "pK = 0.07..."
## [1] "pK = 0.08..."
## [1] "pK = 0.09..."
## [1] "pK = 0.1..."
## [1] "pK = 0.11..."
## [1] "pK = 0.12..."
## [1] "pK = 0.13..."
## [1] "pK = 0.14..."
## [1] "pK = 0.15..."
## [1] "pK = 0.16..."
## [1] "pK = 0.17..."
## [1] "pK = 0.18..."
## [1] "pK = 0.19..."
## [1] "pK = 0.2..."
## [1] "pK = 0.21..."
## [1] "pK = 0.22..."
## [1] "pK = 0.23..."
## [1] "pK = 0.24..."
## [1] "pK = 0.25..."
## [1] "pK = 0.26..."
## [1] "pK = 0.27..."
## [1] "pK = 0.28..."
## [1] "pK = 0.29..."
## [1] "pK = 0.3..."
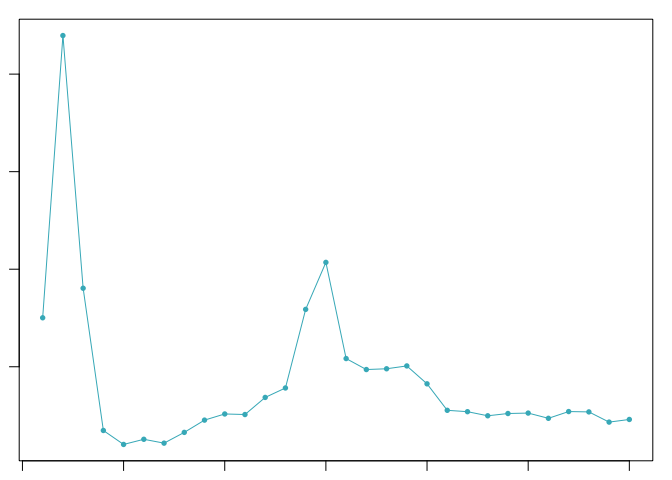
sweep.stats <- summarizeSweep(sweep.res, GT = FALSE)
bcmvn <- find.pK(sweep.stats)
## NULL
pK.set <- unique(sweep.stats$pK)[2]
nExp_poi <- round(0.08*nrow(experiment.data@meta.data))
experiment.data <- doubletFinder_v3(experiment.data, PCs = 1:20, pN = 0.25, pK = as.numeric(as.character(pK.set)), nExp = nExp_poi, reuse.pANN = FALSE, sct = FALSE)
## [1] "Creating 592 artificial doublets..."
## [1] "Creating Seurat object..."
## [1] "Normalizing Seurat object..."
## [1] "Finding variable genes..."
## [1] "Scaling data..."
## [1] "Running PCA..."
## [1] "Calculating PC distance matrix..."
## [1] "Computing pANN..."
## [1] "Classifying doublets.."
The following code can be used if literature assisted cell type identification is available
annotations <- experiment.data@meta.data$seurat_clusters
homotypic.prop <- modelHomotypic(annotations)
nExp_poi <- round(0.08*nrow(experiment.data@meta.data))
nExp_poi.adj <- round(nExp_poi*(1-homotypic.prop))
experiment.data <- doubletFinder_v3(experiment.data, PCs = 1:20, pN = 0.25, pK = as.numeric(as.character(pK.set)), nExp = nExp_poi.adj, reuse.pANN = "pANN_0.25_0.02_142", sct = FALSE)
Remove doublets
experiment.data <- subset(experiment.data, DF.classifications_0.25_0.02_142 == "Singlet")
Session Information
sessionInfo()
## R version 4.1.2 (2021-11-01)
## Platform: x86_64-apple-darwin17.0 (64-bit)
## Running under: macOS Catalina 10.15.7
##
## Matrix products: default
## BLAS: /Library/Frameworks/R.framework/Versions/4.1/Resources/lib/libRblas.0.dylib
## LAPACK: /Library/Frameworks/R.framework/Versions/4.1/Resources/lib/libRlapack.dylib
##
## locale:
## [1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
##
## attached base packages:
## [1] stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] ROCR_1.0-11 KernSmooth_2.23-20 fields_14.0
## [4] viridis_0.6.2 viridisLite_0.4.0 spam_2.8-0
## [7] ggplot2_3.3.5 kableExtra_1.3.4 SeuratObject_4.0.4
## [10] Seurat_4.1.0 DoubletFinder_2.0.3
##
## loaded via a namespace (and not attached):
## [1] Rtsne_0.15 colorspace_2.0-2 deldir_1.0-6
## [4] ellipsis_0.3.2 ggridges_0.5.3 rstudioapi_0.13
## [7] spatstat.data_2.1-2 farver_2.1.0 leiden_0.3.9
## [10] listenv_0.8.0 bit64_4.0.5 ggrepel_0.9.1
## [13] RSpectra_0.16-0 fansi_1.0.2 xml2_1.3.3
## [16] codetools_0.2-18 splines_4.1.2 knitr_1.37
## [19] polyclip_1.10-0 jsonlite_1.8.0 ica_1.0-2
## [22] cluster_2.1.2 png_0.1-7 uwot_0.1.11
## [25] shiny_1.7.1 sctransform_0.3.3 spatstat.sparse_2.1-0
## [28] compiler_4.1.2 httr_1.4.2 assertthat_0.2.1
## [31] Matrix_1.4-0 fastmap_1.1.0 lazyeval_0.2.2
## [34] cli_3.2.0 later_1.3.0 htmltools_0.5.2
## [37] tools_4.1.2 dotCall64_1.0-1 igraph_1.2.11
## [40] gtable_0.3.0 glue_1.6.2 RANN_2.6.1
## [43] reshape2_1.4.4 dplyr_1.0.8 maps_3.4.0
## [46] Rcpp_1.0.8.3 scattermore_0.7 jquerylib_0.1.4
## [49] vctrs_0.3.8 svglite_2.1.0 nlme_3.1-155
## [52] lmtest_0.9-39 xfun_0.29 stringr_1.4.0
## [55] globals_0.14.0 rvest_1.0.2 mime_0.12
## [58] miniUI_0.1.1.1 lifecycle_1.0.1 irlba_2.3.5
## [61] goftest_1.2-3 future_1.23.0 MASS_7.3-55
## [64] zoo_1.8-9 scales_1.1.1 spatstat.core_2.3-2
## [67] promises_1.2.0.1 spatstat.utils_2.3-0 parallel_4.1.2
## [70] RColorBrewer_1.1-2 yaml_2.3.5 reticulate_1.24
## [73] pbapply_1.5-0 gridExtra_2.3 sass_0.4.0
## [76] rpart_4.1.16 stringi_1.7.6 highr_0.9
## [79] systemfonts_1.0.4 rlang_1.0.2 pkgconfig_2.0.3
## [82] matrixStats_0.61.0 evaluate_0.14 lattice_0.20-45
## [85] purrr_0.3.4 tensor_1.5 labeling_0.4.2
## [88] patchwork_1.1.1 htmlwidgets_1.5.4 bit_4.0.4
## [91] cowplot_1.1.1 tidyselect_1.1.2 parallelly_1.30.0
## [94] RcppAnnoy_0.0.19 plyr_1.8.6 magrittr_2.0.2
## [97] R6_2.5.1 generics_0.1.2 DBI_1.1.2
## [100] withr_2.4.3 mgcv_1.8-38 pillar_1.7.0
## [103] fitdistrplus_1.1-6 survival_3.2-13 abind_1.4-5
## [106] tibble_3.1.6 future.apply_1.8.1 hdf5r_1.3.5
## [109] crayon_1.5.0 utf8_1.2.2 spatstat.geom_2.3-1
## [112] plotly_4.10.0 rmarkdown_2.11 grid_4.1.2
## [115] data.table_1.14.2 webshot_0.5.2 digest_0.6.29
## [118] xtable_1.8-4 tidyr_1.2.0 httpuv_1.6.5
## [121] munsell_0.5.0 bslib_0.3.1