
Part 6: Enrichment, Model-Based DE, and Cell-Type Identification
Load libraries
library(Seurat)
library(ggplot2)
library(limma)
library(topGO)
Load the Seurat object
load("clusters_seurat_object.RData")
experiment.merged
## An object of class Seurat
## 21005 features across 10595 samples within 1 assay
## Active assay: RNA (21005 features, 5986 variable features)
## 3 dimensional reductions calculated: pca, tsne, umap
Idents(experiment.merged) <- "finalcluster"
1. Gene Ontology (GO) Enrichment of Genes Expressed in a Cluster
Gene Ontology provides a controlled vocabulary for describing gene products. Here we use enrichment analysis to identify GO terms that are overrepresented among the gene expressed in cells in a given cluster.
cluster12 <- subset(experiment.merged, idents = '12')
expr <- as.matrix(GetAssayData(cluster12))
# Filter out genes that are 0 for every cell in this cluster
bad <- which(rowSums(expr) == 0)
expr <- expr[-bad,]
# Select genes that are expressed > 0 in at least half of cells
n.gt.0 <- apply(expr, 1, function(x)length(which(x > 0)))
expressed.genes <- rownames(expr)[which(n.gt.0/ncol(expr) >= 0.5)]
all.genes <- rownames(expr)
# define geneList as 1 if gene is in expressed.genes, 0 otherwise
geneList <- ifelse(all.genes %in% expressed.genes, 1, 0)
names(geneList) <- all.genes
# Create topGOdata object
GOdata <- new("topGOdata",
ontology = "BP", # use biological process ontology
allGenes = geneList,
geneSelectionFun = function(x)(x == 1),
annot = annFUN.org, mapping = "org.Hs.eg.db", ID = "symbol")
# Test for enrichment using Fisher's Exact Test
resultFisher <- runTest(GOdata, algorithm = "elim", statistic = "fisher")
GenTable(GOdata, Fisher = resultFisher, topNodes = 20, numChar = 60)
## GO.ID Term Annotated Significant Expected Fisher
## 1 GO:0050852 T cell receptor signaling pathway 111 4 0.23 7.4e-05
## 2 GO:0050861 positive regulation of B cell receptor signaling pathway 7 2 0.01 8.7e-05
## 3 GO:0072659 protein localization to plasma membrane 237 5 0.49 0.00011
## 4 GO:0050727 regulation of inflammatory response 218 4 0.45 0.00098
## 5 GO:0021762 substantia nigra development 32 2 0.07 0.00198
## 6 GO:0000304 response to singlet oxygen 1 1 0.00 0.00208
## 7 GO:0042351 'de novo' GDP-L-fucose biosynthetic process 1 1 0.00 0.00208
## 8 GO:2000473 positive regulation of hematopoietic stem cell migration 1 1 0.00 0.00208
## 9 GO:0051623 positive regulation of norepinephrine uptake 1 1 0.00 0.00208
## 10 GO:0032745 positive regulation of interleukin-21 production 1 1 0.00 0.00208
## 11 GO:0072749 cellular response to cytochalasin B 1 1 0.00 0.00208
## 12 GO:0060964 regulation of gene silencing by miRNA 39 2 0.08 0.00294
## 13 GO:1905475 regulation of protein localization to membrane 144 3 0.30 0.00319
## 14 GO:0034113 heterotypic cell-cell adhesion 44 2 0.09 0.00372
## 15 GO:1903615 positive regulation of protein tyrosine phosphatase activity 2 1 0.00 0.00416
## 16 GO:0031022 nuclear migration along microfilament 2 1 0.00 0.00416
## 17 GO:1904155 DN2 thymocyte differentiation 2 1 0.00 0.00416
## 18 GO:0006933 negative regulation of cell adhesion involved in substrate-b... 2 1 0.00 0.00416
## 19 GO:0002728 negative regulation of natural killer cell cytokine producti... 2 1 0.00 0.00416
## 20 GO:0044855 plasma membrane raft distribution 2 1 0.00 0.00416
- Annotated: number of genes (out of all.genes) that are annotated with that GO term
- Significant: number of genes that are annotated with that GO term and meet our criteria for “expressed”
- Expected: Under random chance, number of genes that would be expected to be annotated with that GO term and meeting our criteria for “expressed”
- Fisher: (Raw) p-value from Fisher’s Exact Test
Quiz 1
Challenge Questions
If you have extra time:
2. Model-based DE analysis in limma
limma is an R package for differential expression analysis of bulk RNASeq and microarray data. We apply it here to single cell data.
Limma can be used to fit any linear model to expression data and is useful for analyses that go beyond two-group comparisons. A detailed tutorial of model specification in limma is available here and in the limma User’s Guide.
# filter genes to those expressed in at least 10% of cells
keep <- rownames(expr)[which(n.gt.0/ncol(expr) >= 0.1)]
expr2 <- expr[keep,]
# Set up "design matrix" with statistical model
cluster12$proper.ident <- make.names(cluster12$orig.ident)
mm <- model.matrix(~0 + proper.ident, data = cluster12[[]])
head(mm)
## proper.identA001.C.007 proper.identA001.C.104 proper.identB001.A.301
## AAACCCACAGAAGTTA_A001-C-007 1 0 0
## AAACGCTAGGAGCAAA_A001-C-007 1 0 0
## AAACGCTTCTCTGCTG_A001-C-007 1 0 0
## AAAGAACCACGAAGAC_A001-C-007 1 0 0
## AACAGGGGTCCCTGAG_A001-C-007 1 0 0
## AAGGTAATCCTCAGAA_A001-C-007 1 0 0
tail(mm)
## proper.identA001.C.007 proper.identA001.C.104 proper.identB001.A.301
## TTCCGTGTCCGCTGTT_B001-A-301 0 0 1
## TTCTGTACATAGACTC_B001-A-301 0 0 1
## TTCTTCCAGTCCCAAT_B001-A-301 0 0 1
## TTGGATGCACGGTGCT_B001-A-301 0 0 1
## TTTACGTGTGTCTTAG_B001-A-301 0 0 1
## TTTCGATAGACAACAT_B001-A-301 0 0 1
# Fit model in limma
fit <- lmFit(expr2, mm)
head(coef(fit))
## proper.identA001.C.007 proper.identA001.C.104 proper.identB001.A.301
## CCNL2 0.5986870 0.4153912 0.41790229
## CDK11A 0.7792449 0.1782896 0.22297892
## GNB1 0.8793928 0.6281440 0.73183266
## SKI 0.2834711 0.4465787 0.05454021
## KCNAB2 0.3073824 0.4218045 0.28888714
## CAMTA1 0.1343611 0.2076775 0.47916465
# Test B001-A-301 - A001-C-007
contr <- makeContrasts(proper.identB001.A.301 - proper.identA001.C.007, levels = colnames(coef(fit)))
levels <- colnames(coef(fit))
contr
## Contrasts
## Levels proper.identB001.A.301 - proper.identA001.C.007
## proper.identA001.C.007 -1
## proper.identA001.C.104 0
## proper.identB001.A.301 1
fit2 <- contrasts.fit(fit, contrasts = contr)
fit2 <- eBayes(fit2)
out <- topTable(fit2, n = Inf, sort.by = "P")
head(out, 30)
## logFC AveExpr t P.Value adj.P.Val B
## SLC26A2 2.8822283 1.0629482 18.098433 6.268188e-52 1.212894e-48 106.877809
## XIST 1.4542383 0.3657630 12.730437 1.083975e-30 1.048746e-27 58.888645
## PHGR1 1.9590238 0.7501501 12.122078 2.071322e-28 1.336003e-25 53.731545
## GUCA2A 1.5400474 0.4334461 12.078235 3.013116e-28 1.457595e-25 53.363616
## SLC26A3 1.7533252 0.6555777 11.370757 1.180260e-25 4.567607e-23 47.503355
## PDE3A 1.4602304 0.4332776 11.190702 5.261502e-25 1.696834e-22 46.036641
## MT-CO2 -1.9796188 2.7289681 -10.328533 5.771672e-22 1.595455e-19 39.170184
## PIGR 1.8777320 1.3447380 8.986565 1.713251e-17 4.143926e-15 29.082220
## ATP1A1 1.4211688 0.6672922 8.878497 3.787588e-17 8.143314e-15 28.306074
## CLCA4 1.0493355 0.3366567 8.657707 1.881022e-16 3.639779e-14 26.738694
## CKB 1.7948701 1.4913849 8.543888 4.255755e-16 7.486260e-14 25.940527
## MUC12 1.2885756 0.5705467 8.456585 7.924369e-16 1.277804e-13 25.332934
## CCND3 1.7789964 1.3641127 8.236113 3.740579e-15 5.567709e-13 23.816805
## FKBP5 1.7713394 1.3421646 8.129783 7.832342e-15 1.082542e-12 23.095140
## PARP8 1.4550661 0.9387516 7.408418 9.944179e-13 1.282799e-10 18.371304
## RNF213 -1.5051780 1.4710884 -6.798509 4.673553e-11 5.652079e-09 14.626670
## FTH1 1.0852623 0.6892685 6.769212 5.589514e-11 6.362182e-09 14.452875
## PIP4K2A 1.4152607 1.1825719 6.759170 5.942364e-11 6.388042e-09 14.393437
## S100A6 1.3140613 0.9677000 6.559153 1.983667e-10 2.020208e-08 13.223694
## NXPE1 0.9531856 0.4764160 6.342688 7.094551e-10 6.741109e-08 11.988575
## TMSB4X 1.2496508 1.0055437 6.337401 7.315932e-10 6.741109e-08 11.958816
## CEACAM7 0.8182380 0.3321876 6.196347 1.648992e-09 1.450363e-07 11.172106
## SATB2 0.9949205 0.5617362 5.999302 5.014199e-09 4.218467e-07 10.096854
## MUC13 0.9554270 0.5686166 5.975058 5.738627e-09 4.570052e-07 9.966490
## HSP90AA1 -1.0299812 0.6331681 -5.969930 5.904459e-09 4.570052e-07 9.938973
## FABP1 0.9958427 0.5854007 5.918083 7.867180e-09 5.854998e-07 9.661821
## FCGBP 0.7940343 0.3592995 5.660737 3.177359e-08 2.277107e-06 8.315487
## NCL -0.8218150 0.4153055 -5.651066 3.345371e-08 2.311890e-06 8.265849
## RPL13 -1.1459746 1.0205946 -5.632584 3.690815e-08 2.462664e-06 8.171197
## SELENOP 0.7471779 0.3588361 5.500210 7.406662e-08 4.777297e-06 7.500782
Output columns:
- logFC: log fold change (since we are working with Seurat’s natural log transformed data, will be natural log fold change)
- AveExpr: Average expression across all cells in expr2
- t: logFC divided by its standard error
- P.Value: Raw p-value (based on t) from test that logFC differs from 0
- adj.P.Val: Benjamini-Hochberg false discovery rate adjusted p-value
- B: log-odds that gene is DE
Quiz 2
BONUS: Cell type identification with scMRMA
scMRMA (single cell Multi-Resolution Marker-based Annotation Algorithm) classifies cells by iteratively clustering them then annotating based on a hierarchical external database.
The databases included with the current version are only for use with human and mouse, but a user-constructed hierarchichal database can be used.
The package can be installed from Github:
# Remove hashes to run
# install.packages("devtools")
# devtools::install_github("JiaLiVUMC/scMRMA")
suppressPackageStartupMessages(library(scMRMA))
result <- scMRMA(input = experiment.merged,
species = "Hs",
db = "panglaodb")
## Pre-defined cell type database panglaodb will be used.
## Multi Resolution Annotation Started.
## Level 1 annotation started.
## Level 2 annotation started.
## Level 3 annotation started.
## Level 4 annotation started.
## Uniform Resolution Annotation Started.
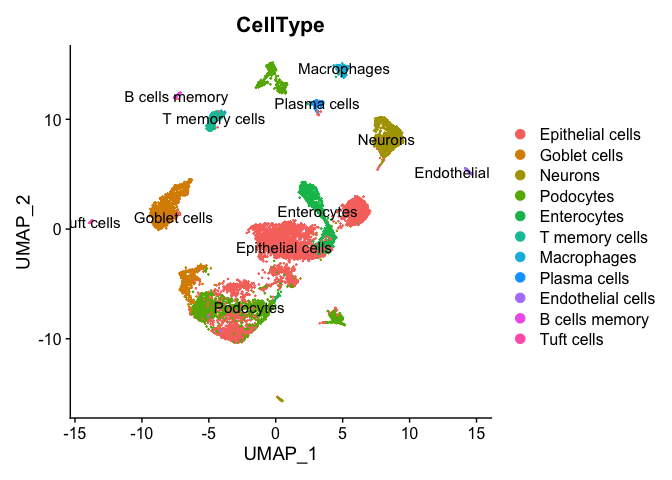
table(result$uniformR$annotationResult)
##
## Epithelial cells Goblet cells Neurons Podocytes Enterocytes T memory cells Macrophages Plasma cells Endothelial cells B cells memory Tuft cells
## 4556 1356 978 1992 819 329 195 142 99 80 49
## Add cell types to metadata
experiment.merged <- AddMetaData(experiment.merged, result$uniformR$annotationResult, col.name = "CellType")
table(experiment.merged$CellType, experiment.merged$orig.ident)
##
## A001-C-007 A001-C-104 B001-A-301
## Epithelial cells 202 1315 3039
## Goblet cells 56 361 939
## Neurons 936 10 32
## Podocytes 319 1292 381
## Enterocytes 0 20 799
## T memory cells 79 164 86
## Macrophages 94 64 37
## Plasma cells 75 44 23
## Endothelial cells 7 51 41
## B cells memory 4 49 27
## Tuft cells 2 46 1
table(experiment.merged$CellType, experiment.merged$finalcluster)
##
## 0 3 1 2 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 22 23 24 26
## Epithelial cells 1178 133 12 885 21 673 551 174 6 227 356 13 4 1 263 1 10 2 1 7 0 0 0 0 38
## Goblet cells 2 28 0 1 668 2 2 5 1 0 7 370 0 268 2 0 0 0 0 0 0 0 0 0 0
## Neurons 0 1 909 2 1 2 0 5 0 0 7 0 3 0 1 0 0 3 0 0 0 0 0 44 0
## Podocytes 2 757 1 1 0 1 117 452 1 1 25 5 0 0 5 269 199 0 156 0 0 0 0 0 0
## Enterocytes 5 0 0 2 0 1 0 4 626 177 0 0 1 3 0 0 0 0 0 0 0 0 0 0 0
## T memory cells 0 0 0 0 0 1 2 0 0 0 3 0 317 0 0 0 0 5 0 1 0 0 0 0 0
## Macrophages 0 0 0 4 0 2 0 0 0 0 0 0 3 0 0 0 0 186 0 0 0 0 0 0 0
## Plasma cells 0 0 0 0 0 0 1 0 0 0 1 1 1 0 0 0 0 0 0 138 0 0 0 0 0
## Endothelial cells 0 2 1 0 0 0 1 0 0 0 2 0 0 0 0 0 0 0 0 0 92 1 0 0 0
## B cells memory 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 79 0 0 0
## Tuft cells 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 49 0 0
DimPlot(experiment.merged, group.by = "CellType", label = TRUE)
Get the next Rmd file
download.file("https://raw.githubusercontent.com/msettles/2022-Uganda-Single-Cell-RNA-Seq-Analysis/main/data_analysis/scRNA_Workshop-PART7.Rmd", "scRNA_Workshop-PART7.Rmd")
Session Information
sessionInfo()
## R version 4.1.2 (2021-11-01)
## Platform: x86_64-apple-darwin17.0 (64-bit)
## Running under: macOS Catalina 10.15.7
##
## Matrix products: default
## BLAS: /Library/Frameworks/R.framework/Versions/4.1/Resources/lib/libRblas.0.dylib
## LAPACK: /Library/Frameworks/R.framework/Versions/4.1/Resources/lib/libRlapack.dylib
##
## locale:
## [1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
##
## attached base packages:
## [1] stats4 stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] scMRMA_1.0 networkD3_0.4 data.tree_1.0.0 tidyr_1.2.0 RANN_2.6.1 plyr_1.8.6 irlba_2.3.5 Matrix_1.4-0 org.Hs.eg.db_3.14.0 topGO_2.46.0 SparseM_1.81 GO.db_3.14.0 AnnotationDbi_1.56.2 IRanges_2.28.0 S4Vectors_0.32.3 Biobase_2.54.0 graph_1.72.0 BiocGenerics_0.40.0 limma_3.50.0 ggplot2_3.3.5 SeuratObject_4.0.4
## [22] Seurat_4.1.0
##
## loaded via a namespace (and not attached):
## [1] igraph_1.2.11 lazyeval_0.2.2 splines_4.1.2 listenv_0.8.0 scattermore_0.7 usethis_2.1.5 GenomeInfoDb_1.30.0 digest_0.6.29 htmltools_0.5.2 fansi_1.0.2 magrittr_2.0.2 memoise_2.0.1 tensor_1.5 cluster_2.1.2 ROCR_1.0-11 remotes_2.4.2 globals_0.14.0 Biostrings_2.62.0 matrixStats_0.61.0
## [20] spatstat.sparse_2.1-0 prettyunits_1.1.1 colorspace_2.0-2 blob_1.2.2 ggrepel_0.9.1 xfun_0.29 dplyr_1.0.8 callr_3.7.0 crayon_1.5.0 RCurl_1.98-1.5 jsonlite_1.8.0 spatstat.data_2.1-2 survival_3.2-13 zoo_1.8-9 glue_1.6.2 polyclip_1.10-0 gtable_0.3.0 zlibbioc_1.40.0 XVector_0.34.0
## [39] leiden_0.3.9 pkgbuild_1.3.1 future.apply_1.8.1 abind_1.4-5 scales_1.1.1 DBI_1.1.2 miniUI_0.1.1.1 Rcpp_1.0.8.3 viridisLite_0.4.0 xtable_1.8-4 reticulate_1.24 spatstat.core_2.3-2 bit_4.0.4 htmlwidgets_1.5.4 httr_1.4.2 RColorBrewer_1.1-2 ellipsis_0.3.2 ica_1.0-2 farver_2.1.0
## [58] pkgconfig_2.0.3 sass_0.4.0 uwot_0.1.11 deldir_1.0-6 utf8_1.2.2 labeling_0.4.2 tidyselect_1.1.2 rlang_1.0.2 reshape2_1.4.4 later_1.3.0 munsell_0.5.0 tools_4.1.2 cachem_1.0.6 cli_3.2.0 generics_0.1.2 RSQLite_2.2.9 devtools_2.4.3 ggridges_0.5.3 evaluate_0.14
## [77] stringr_1.4.0 fastmap_1.1.0 yaml_2.3.5 goftest_1.2-3 processx_3.5.2 fs_1.5.2 knitr_1.37 bit64_4.0.5 fitdistrplus_1.1-6 purrr_0.3.4 KEGGREST_1.34.0 pbapply_1.5-0 future_1.23.0 nlme_3.1-155 mime_0.12 brio_1.1.3 compiler_4.1.2 rstudioapi_0.13 plotly_4.10.0
## [96] png_0.1-7 testthat_3.1.2 spatstat.utils_2.3-0 tibble_3.1.6 bslib_0.3.1 stringi_1.7.6 highr_0.9 ps_1.6.0 desc_1.4.0 lattice_0.20-45 vctrs_0.3.8 pillar_1.7.0 lifecycle_1.0.1 spatstat.geom_2.3-1 lmtest_0.9-39 jquerylib_0.1.4 RcppAnnoy_0.0.19 data.table_1.14.2 cowplot_1.1.1
## [115] bitops_1.0-7 httpuv_1.6.5 patchwork_1.1.1 R6_2.5.1 promises_1.2.0.1 KernSmooth_2.23-20 gridExtra_2.3 parallelly_1.30.0 sessioninfo_1.2.2 codetools_0.2-18 pkgload_1.2.4 MASS_7.3-55 assertthat_0.2.1 rprojroot_2.0.2 withr_2.4.3 sctransform_0.3.3 GenomeInfoDbData_1.2.7 mgcv_1.8-38 parallel_4.1.2
## [134] grid_4.1.2 rpart_4.1.16 rmarkdown_2.11 Rtsne_0.15 shiny_1.7.1